一、背景
随着业务的快速变化,应用程序通信和集成变得更加重要。一个坚固的、成熟的、紧密耦合的通信基础设施成为了数字企业真正的基础,它让企业可以快速地应对变化。近年来,最有前景的数字通信方法来自开源社区,开发人员在这里合作,为构建数字世界的共同挑战提供解决方案。这些解决方案有 Kafka,RabbitMQ等。因为满足不断变化的业务需求需要仔细考虑,所以在本白皮书中,我们定义了几个开源或商业选项,并列出了它们的优点、缺点以及相关复杂性和成本信息。
二、messaging 简介
当计算机开始通讯时,messaging 就成为了系统之间通讯的基础。最开始的消息传递是在阿帕网,它是第一个广域分组交换网络,使用以太网、TCP/IP等网络层协议,来进行系统间的通讯。随着阿帕网的发展,更多的系统相互连接,成为今天的互联网,通信原则开始从网络层进入到应用层。随着这些进步,抽象层出现了,简化了系统连接和通信的方式,这也成为消息传递技术的目标。
多年来,为不同类型的通信发明了新的通信协议。Java消息服务(JMS)和数据分发服务(DDS)规范协议在90年代末和21世纪初出现。许多应用程序开始使用像HTML和HTTP这样的协议,而不是最初设计的协议。每个人都在寻找一个协议,它可以适用于任何东西,但现实是,永远不会有一个单一的通信方法。数字通信将始终是多种方法和模式的混合体。
三、各个MQ简介
1. RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求在其次。RabbitMQ的可靠性是非常好的,数据能够保证百分之百的不丢失。可以使用镜像队列,它的稳定性非常好。在性能不如 Kafka,但也可以做一些性能上的优化。
特性
1. 所需的技能
了解AMQP协议和规范。
2. 复杂性
API 和协议级别的通用数据交换方法意味着数据分发的选项呈指数级增长。
3. 优点
- 基于AMQP协议,操作行为的定义非常明确
- 简易灵活的部署方式
- 在低吞吐量的情况下,有着非常低延迟
- 文档丰富和社区活跃
4. 缺点
- 吞吐量限制,单机峰值约万/s
- 维护复杂,在弹性伸缩、高可用性、数据复制等不如 pulsar、kafka
- 缺乏本地流处理、消息回溯、消息压缩等
5.总成本
RabbitMQ 易于部署和维护。但是由于是Erlang开发的,功能扩展和二次开发代价高。
6. 性能
- 并发一般,万级别 TPS
- 延迟低,微秒级别
- 可扩展性一般
- 支持分布式,RabbitMQ 是为大规模部署而设计的,但通常需要大规模的服务器基础架构来支持可扩展的环境,以及复杂的路由来支持全球分布式结构
2.RocketMQ
RocketMQ 是由阿里巴巴消息中间件团队研发的一款高性能、高吞吐量、低延迟、高可用、高可靠的分布式消息中间件,参考了优秀的开源消息中间件Kafka,天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商领域中,以及业务削峰。开源后并于2016年捐赠给Apache社区孵化,目前已经成为了Apache顶级项目。
特性
1. 所需的技能
需要对消息传递,消息事物,消息重试机制等原理有基本理解。
2. 复杂性
相对于 kafka,不需要部署额外的 Zookeeper,内置了 nameserver ,部署简单。
3. 优点
- 满足多种需求,支持有序消息、延迟消息、消息回溯、消息积压等等
- 保证高可用,能够大规模集群化部署
- java 开发,阅读源代码、扩展、二次开发方便
4. 缺点
- 消息重复问题,它不能保证不重复
- 延迟消息,只支持固定 level
- 社区活跃度和文档都相较一般
5. 总成本
RocketMQ 易于部署和维护,但与任何开源解决方案一样,随着基础设施的扩展,支持和维护它的成本也会增加。
6. 性能
- 并发高,十万级别 TPS
- 延迟低,毫秒级别
- 可扩展性强,集群可以同时进行水平方向和垂直方向的缩放
- 支持分布式,原生支持高可用集群,分布式扩展设计
3.Kafka
Kafka 是一个分布式、分区的、多副本的,基于 zookeeper 协调的分布式日志系统(也可以当做 MQ 系统),常见可以用于 web/nginx 日志、访问日志,消息服务等。由 Linkedin 公司开发,于2010年贡献给了 Apache 基金会并成为顶级开源项目。
特性
1. 所需的技能
了解消息传递和底层操作系统功能,如存储和网络通信。需要学习其他组件,如Zookeeper等。
2. 复杂性
相对容易开箱即用。当需要诸如安全性、复制和全局分发等功能时,复杂性就会增加。
3. 优点
- 性能强大,拥有百万级的吞吐量
- 支持数据持久、分布式流处理、跨域复制等功能
- 与周边系统的兼容性好,尤其是大数据和流计算领域,几乎所有相关的开源软件都支持Kafka
- 文档丰富和社区活跃
4. 缺点
- 没有与租户完全隔离的本地多租户
- 长期存储数据昂贵,尽管可以长时间存储,但是由于成本问题却很少用到它
- 运维困难,必须提前计划和计算 broker、topic、分区和副本的数量(确保计划的未来使用量增长),以避免扩展问题
- 在大量 topic 下,吞吐量会大幅下降
5. 总成本
Kafka 很简单,相对容易启动和运行,特别是对于中小型项目。开源并不意味着免费,Kafka 不断达到企业规模需要专门的支持人员来维护基础设施。
6. 性能
- 并发高,百万级别 TPS
- 延迟低,毫秒级别
- 可扩展性好,集群可以同时进行水平方向和垂直方向的缩放
- 支持分布式
4.ADMQ
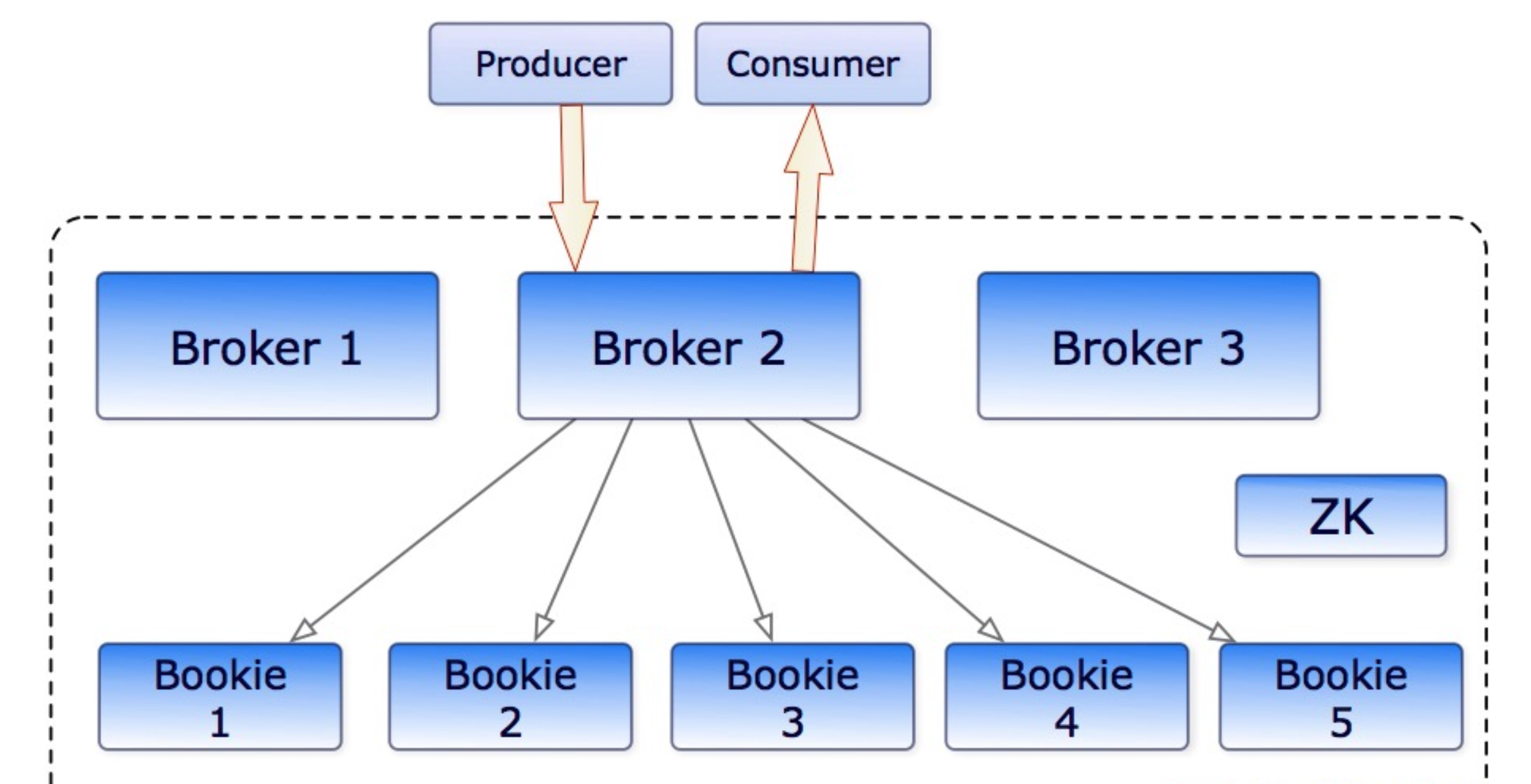
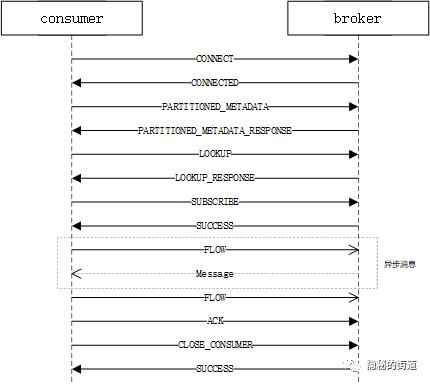
ADMQ 是基于Apache Pulsar 的二次开发消息中间件,是下一代云原生分布式消息流平台。在许多方面,Pulsar 与 Kafka 相似,但在规划部署方面差别很大。Pulsar 最初只是传统的消息传递系统,后面加入了流处理的功能。这对于那些希望部署大规模系统同时要求更少的复杂性的用户来说是非常有吸引力的。Pulsar 企业级的分布式对于多租户和数据复制的功能提供了一个开箱即用的支持,从而简化了随着时间的推移不断增长的资源使用和采用。
特性
1. 所需的技能
对消息传递和底层操作系统功能的基本理解,如存储和网络通信。需要学习其他组件,如Zookeeper,Bookkeeper等。
2. 复杂性
一种简化的封装方法,其中所有功能都可以集中访问,从而降低了扩展到企业级别时的复杂性。
3. 优点
- 性能强大,比 kafka 更稳定的低延迟、高吞吐量
- 存储与计算分离,无需移动数据即可添加或使用 broker,运维方便
- 分层存储,历史数据可以使用其他廉价的存储
- 地理复制和内置 Discovery,易于将集群复制到多个区域
- 多租户,不同的团队可以使用相同的集群并将其隔离,解决了许多管理难题
- Function,易于部署、轻量级计算过程、对开发人员友好的 API,无需运行自己的流处理引擎
- 多协议支持,支持 RocketMQ、AMQP、Kafka 协议等,容易与实现这些协议的中间件进行集成
- 社区相对活跃,能够及时反馈。
4. 缺点
- 部署比较复杂,除了 Pulsar 还有另外有Zookeeper、Bookkeeper两个组件
- 相对缺乏支持、文档和案例
- 插件和客户端相对 Kafka 较少
5. 总成本
Pulsar 需要花费更多的精力来启动和运行,但一旦部署,它就可以很好地扩展到企业级别。开源并不意味着免费的,企业运行 Pulsar 通常需要专门的支持人员来维护基础设施。使用ADMQ商业版,金蝶天燕可以提供完美支持和维护。
6. 性能
并发高,百万级别 TPS
延迟低,毫秒级别
可扩展性强,集群可以同时进行水平方向和垂直方向的缩放
支持分布式,内置了分布式和数据复制的本地支持
四、总结
如今,在选择消息传递通信产品时,企业比其他任何时候都面临着困难的挑战。虽然单个解决方案的总体拥有成本较低,但没有一个解决方案能够满足所有应用程序的所有需求。消息传递必须更加全面,以满足特定和不同的应用程序需求—包括高性能/低延迟事件处理、流分析的流数据、不同应用程序之间本地集成的微服务等等。
如今 ADMQ 将流处理和传统消息队列统一,加上跨地域复制、无状态broker、分层存储、多协议支持,让 ADMQ 成为一个全新的消息中间件。提供给不同企业不同需求的对应解决方案。
对比概览
| 对比项 | RabbitMQ(AMQP) | RocketMQ | Kafka | ADMQ |
|---|---|---|---|---|
| 成熟度 | 成熟 | 成熟 | 成熟 | 一般 |
| 时效性 | 微秒级别 | 毫秒级别 | 毫秒级别 | 毫秒级别 |
| 请求TPS | 万级别 | 十万级别 | 百万级别 | 百万级别 |
| 可靠性 | 一般 | 高 | 一般 | 高 |
| 可用性 | 高(主从构架) | 高(主从构架) | 非常高(分布式) | 非常高(分布式) |
| 定时消息 | 支持 | 支持(固定level) | 不支持 | 支持 |
| 事物 | 支持 | 支持 | 支持 | 支持 |
| 副本同步策略 | Master-Slave同步 | Master-Slave同步 | 多机异步 | 多机异步 |
| 多租户 | 支持部分 | 支持部分 | 支持部分 | 支持 |
| 动态扩容 | 集群扩容依赖前端 | 需同步配置 | 需手动执行rebalance | 友好,及时扩容 |
| 故障恢复 | 不友好 | 不友好 | 较友好 | 友好 |
| 消息堆积能力 | 影响性能 | 支持 | 支持 | 支持 |
| 消息回溯 | 不支持 | 支持 | 支持 | 支持 |
| 顺序消息 | 不支持 | 支持 | 支持 | 支持 |
| 安全防护 | 一般 | 一般 | 一般 | 高 |
| 社区活跃度 | 高 | 中 | 高 | 高 |
| 文档 | 多 | 中 | 多 | 一般 |
| 特点 | erlang语言发开,性能一般,出现比较早,有一定的用户基数 | 各个环节分布式扩展设计,主从HA,多种消费模式,性能好 | 高吞吐量、持久化数据存储、分布式系统易于扩展,性能极好 | 灵活、多租户、云原生架构、跨地域复制,性能极好 |