一、概念
bookkeeper 类似于一个日志存储系统。
1. Ledger
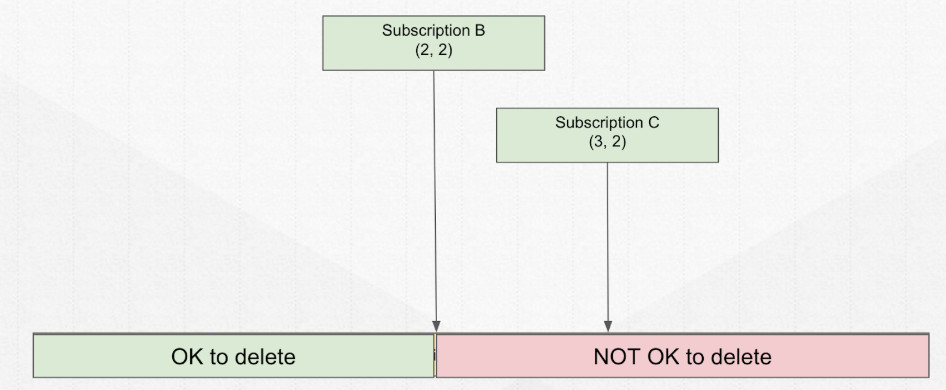
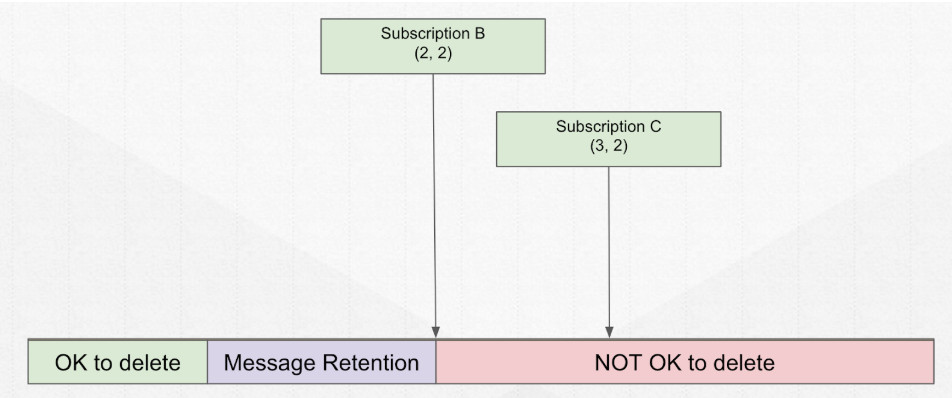
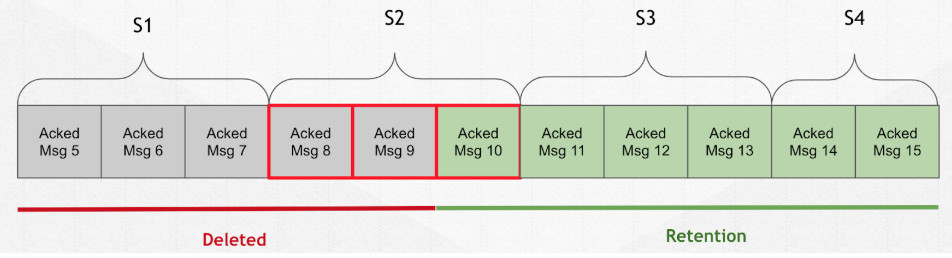
Ledger 创建了之后,进行写数据、关闭和删除操作。

Legder 元数据的存储。结构如上图
参数的含义
state :Ledger 的开关状态,open、close
last entry id : 上一次确认的entry id, entry id 是从 0 开始递增的
ensemble / write quorum / ack quorum :ledger 存放位置的复制信息
2. Entry
entry 的元数据信息
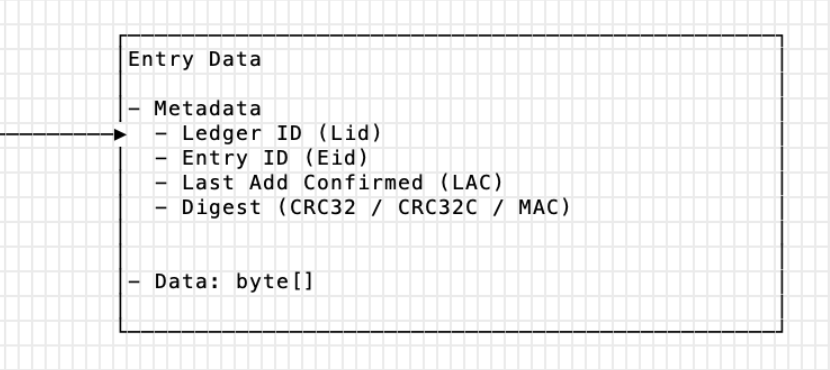
参数的含义
Lid 和 Eid : 记录的是 entry 的key
LAC : 最后一条已经添加的记录
Digest :记录字节的数据,用于完整性校验
上面介绍的 entry 和 Ledger 的元数据都会存入 Zookeeper 中。
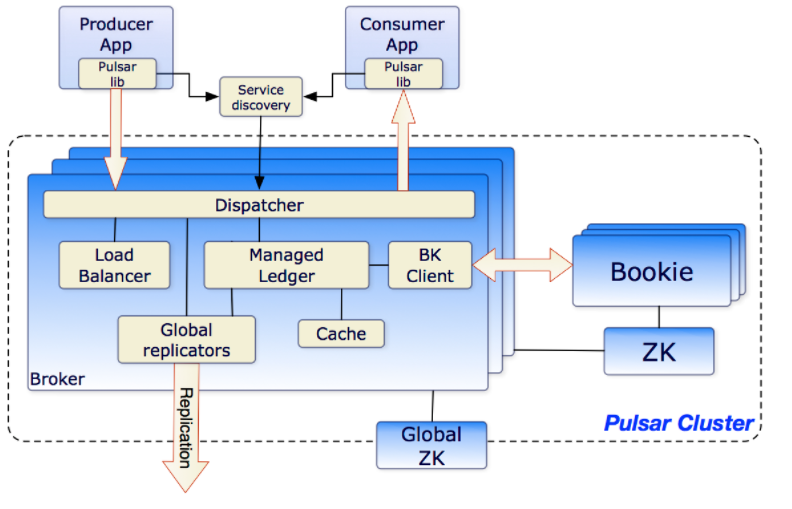
二、架构
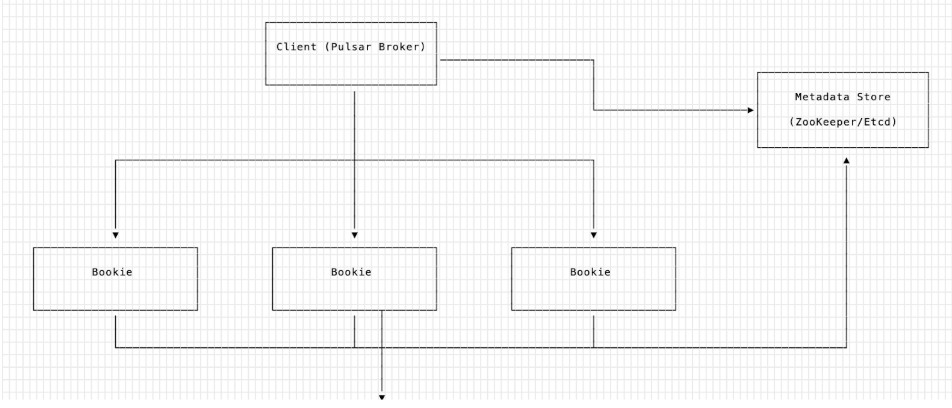
3大组件
1. zookeeper
存储元数据信息
2. client
实现一致性、策略性相关的逻辑
3. bookie
存储 ledger 对应的 entry ,所有的 bookie 都会存储到 Bookkeeper 上,让客户端发现
bookie 可以看做是一个 key-value 数据库。其中 key 就是 (lid + eid),value 就是 ledger 中的 entry 。

bookie 的实现是依靠 journal 和 ledger storage。
3.1 journal
journal 只有写操作,bookie 负责顺序把 entry 写到 journal 文件里,不会进行随机访问。
写满了一个 journal 之后,bookie 就会开启一个新的 journal 文件,继续按照顺序写 entry。
索引 write cache
journal 中的 entry 是没办法查询的,这个时候就需要索引来达到高效查询了。
write cache:bookie 端每次在写 entry 进 journal 的时候,会进行一个写缓存的操作。
写缓存的操作时,bookie 会对 entry 进行排序, 按 ledger 的来源进行划分,为了 entry 可以按照 ledger 进行排序。
当缓存写满时,bookie 会把 write cache 刷到磁盘中。flush 的过程中会进行重新整理成几个目录。一个是 ledger index,用来存储 entry key,一个是 entry log,用来存储 value。
3.2 ledger storage
两种方式,DB ledger storage 和 Sorted ledger storage,实现途径是一样的,就是索引存储的时候不太一样。
三、数据流动
bookie 的操作基本都是再客户端完成和实现的,比如副本复制、读写 entry 等操作。
data flow 是如何在客户端中实现的。
ledger 元数据中的几个参数
- Ensemble —— 用哪几台 bookie 去存储 ledger 对应的 entry
- Write Quorum ——对于一条 entry,需要存多少副本
- Ack Quorum —— 在写 entry 时,要等几个 response
默认情况下是(3,3,3),一共三个 bookie 去存储 ledger 对应的 entry,对于一个 entry,需要 3 个副本, 只有当3个 bookie 返回 response,才会确认。
四、恢复
1. Ledger Recovery
假设有一个 broker1 去写数据,不断地 append entry 到 ledger x ,当 T0 时间点更新 LAC 为 2, 这时发出的 entry3 是还没有得到请求回复的。这时的 entry3 的状态时 outstanding
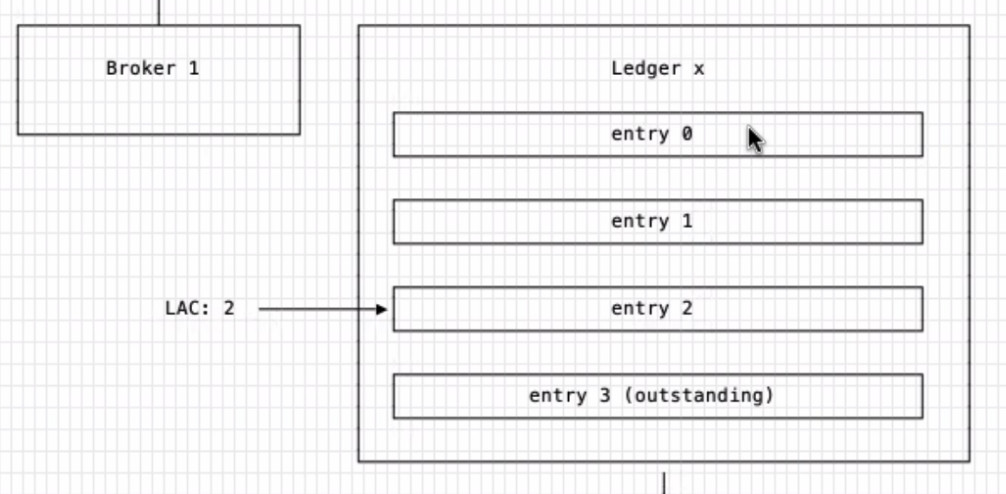
此时因为脑裂,broker2 去接管这个 topic 的写入, 尝试打开 ledger x 却发现他是 open 状态。 这个状态是无法继续进行读写操作的,那么 broker2 就对 ledger x 进行恢复操作 – Ledger Recovery
Ledger Recovery 流程
- 此时返回当前 ledger 里最大的 LAC 数值,然后进行 recovery 的操作执行
- 开始 recovery 操作之后,如果 broker1 还打算继续操作 ledger ,会收到 【操作失败】提醒,此时 broker1 知道当前这个 ledger 被其他 broker 使用后,会放弃所属权。
- 由于 entry3 处于 outstanding 的状态, 还没有被写到 bookie 上。 继续往下读,发现没有 bookie 对下面的数据读写,就会采取关闭的操作,并将最后一条 entry 写回去。
- 开启一个新的 ledger ,开始写入
2. Bookie Recovery
todo。。。。。